Classification
Forecasting
Predicting an Automobile's Fuel Economy (MPG)
In the following tutorial we will take a step by step tour through the creation and use of a regression model built by the Nexosis API.
See our guide for a quick overview of the process. We’ll be using the Auto MPG Data Set from UC Irvine1 for this tutorial. You can download a prepared JSON version from our public repository at https://s3.us-east-2.amazonaws.com/nexosis-api-sample-data/auto-mpg.data.json.
Getting Started
We like to think of using the Nexosis API as a 1-2-3 process of: 1) load your data 2) create your model 3) predict using your model. It really can be that simple - and hopefully this walk through can help you understand how to work with your own dataset so that you’ll see it too.
Step 1 - Load Your Data
As I said above we’re going to use the Auto MPG data for this. The raw data available as TSV is in pretty good shape but we’ll want to make some changes first in order to load it to the Nexosis API. First, we don’t accept TSV directly so we at least need to reformat into a CSV or JSON.
For this purpose I like to use MS Excel®’s data import feature and then save as a CSV. I want to make a few changes to the data while I have it in Excel®.
First, this data has no header so I’m going to name the columns.
Secondly, we have several numeric columns where missing values have been identified by a ‘?’ character. This will cause the Nexosis API to treat the whole column as a string because it doesn’t know what to do with that character. At the time of processing everything has to become a number and we can’t possibly know what the intent of every DataSet value is - so we try not to guess too much. In this case let’s just make every ‘?’ into an empty string instead.
Finally, I’m going to change the car name column. The column description on the UCI website says every value is unique. That won’t help us predict anything and yet I have a suspicion that a 1970’s Honda is more fuel efficient than a Chevy. Turns out that the first word in every name is the make so I’m going to pull out that value into its own column - ‘make’. But wait - that’s a string value and I said everything has to become a number, right? That is true - but strings can be numbers if we just encode them that way. In this case the make column will be split into several columns by the Nexosis API. If you specify a string column as a feature we will doing something called “one hot encoding” to create a column of binary values where a ‘1’ indicates that the row had that string value and a ‘0’ otherwise.
Specifying Metadata
In this case I want the final form to be JSON so I’m going to pass the final CSV into my favorite utility website of late - http://www.csvjson.com.
After I have the dataset in a JSON array it should look something like this:
[{
"MPG": 24,
"Cylinders": 4,
"Displacement": 120,
"Horsepower": 97,
"Weight": 2489,
"Acceleration": 15,
"ModelYear": 74,
"Origin": 3,
"Name": "honda civic",
"Make": "honda"
}]
albeit with several more objects in the array. The reason I want JSON is so I can specify metadata when I load the dataset. I could add it afterward (and would have to on a larger dataset) but this data will all load in one request and then I won’t have to modify the data any further. You can read more about metadata in the concepts section. The short of it here is that I want to make sure the numeric columns are ‘numericmeasure’ and modify the ‘name’ column to indicate that it is not a feature.
{
"columns": {
"MPG": {
"type": "numericMeasure",
"role": "target"
},
"Cylinders": {
"type": "numericMeasure",
"role": "feature"
},
"Displacement": {
"type": "numericMeasure",
"role": "feature"
},
"Horsepower": {
"type": "numericMeasure",
"role": "feature"
},
"Weight": {
"type": "numericMeasure",
"role": "feature"
},
"Acceleration": {
"type": "numericMeasure",
"role": "feature"
},
"ModelYear": {
"type": "string",
"role": "feature",
"imputation": "mode"
},
"Origin": {
"type": "numeric",
"role": "feature",
"imputation": "mode"
},
"Name": {
"type": "string",
"role": "none"
},
"Make": {
"type": "string",
"role": "feature"
}
}
With my JSON file ready I can submit it as the body of an HTTP PUT request to
https://ml.nexosis.com/v1/data/mpg
The ‘mpg’ at the end of that request is indicating a name for the uploaded dataset. We have data and are ready to build a model.
Step 2 - Create a Model
At this point we are ready to let the Nexosis API take over and run all the algorithms to find the best model of our MPG DataSet. In order to create a model we start a model building session by submitting an HTTP POST request to
https://ml.nexosis.com/v1/sessions/model
In the body of the request we need to indicate a minimum of two things: 1) Which data source are we building a model for? and 2) Which class of algorithm are creating a model for? The data source is identified by the dataSourceName field and we call the class of algorithm the predictionDomain. What is a prediction domain? It’s a class of algorithm and naming stuff is hard - so just put ‘regression’ in there and don’t worry about it. Your request body would then be
{
"dataSourceName": "MPG",
"predictionDomain": "Regression"
}
Simple, right? We don’t need much information here because we already identified the column metadata - including the target prediction column - in our initial upload of the data. If you didn’t do that, or if you wanted to modify what the model was built on, then you could submit the target column and column metadata in this request. Any information in the session request will override what was submitted previously - just for that session.
We now wait for the engines to spin in the Nexosis API and figure out the model for our DataSet. This can take from a minute or two to an hour or two depending on the shape of the DataSet. In this case we should have a model in about 10 minutes.
The initial session POST would have responded with a JSON body which in part contained a field called SessionId. This sessionId is a unique identifier for your session and is what you’ll use to get status and eventually results. You can get session status by sending an HTTP HEAD request to
https://ml.nexosis.com/v1/sessions/{your sessionId}
Once you get a status back of completed you’re ready to go get the results. You get results by sending an HTTP GET request to
https://ml.nexosis.com/v1/sessions/{your sessionId}/results
The session results will contain two interesting bits of data. The most important is the modelId field which contains the unique id for the newly created model. This is the information you need in order to make predictions based on the model. The other interesting bit is the data field itself. Within the data field we will send back the values used in testing the model. Whenever you build a model you hold back a portion of the DataSet (typically around 20%) in order to test how well the model does. In the data field you’ll get back that test set with the predictions and the original (actual) values. Actual values have the :actual suffix as shown below.
{
"metrics": {
"meanAbsoluteError": 2.2783203868159472,
"meanAbsolutePercentError": 0.11163053437314517,
"rootMeanSquareError": 2.9862749292063593
},
"data": [{
"mpg": "17.5010826872092",
"Make": "plymouth",
"Origin": "1",
"Weight": "3439",
"Cylinders": "6",
"ModelYear": "71",
"Horsepower": "105",
"mpg:actual": "16",
"Acceleration": "15.5",
"Displacement": "225"
},
...Other data objects elided...
],
"sessionId": "015f064e-957d-4c88-9974-13c08f0cabe4",
"type": "model",
"status": "completed",
"predictionDomain": "regression",
"modelId": "1d8d59be-7eff-4e76-ad3e-d5fc3c59eb58",
... and some other stuff...
}
For illustration purposes I’ve pulled back the MPG results in the Ruby Sample App
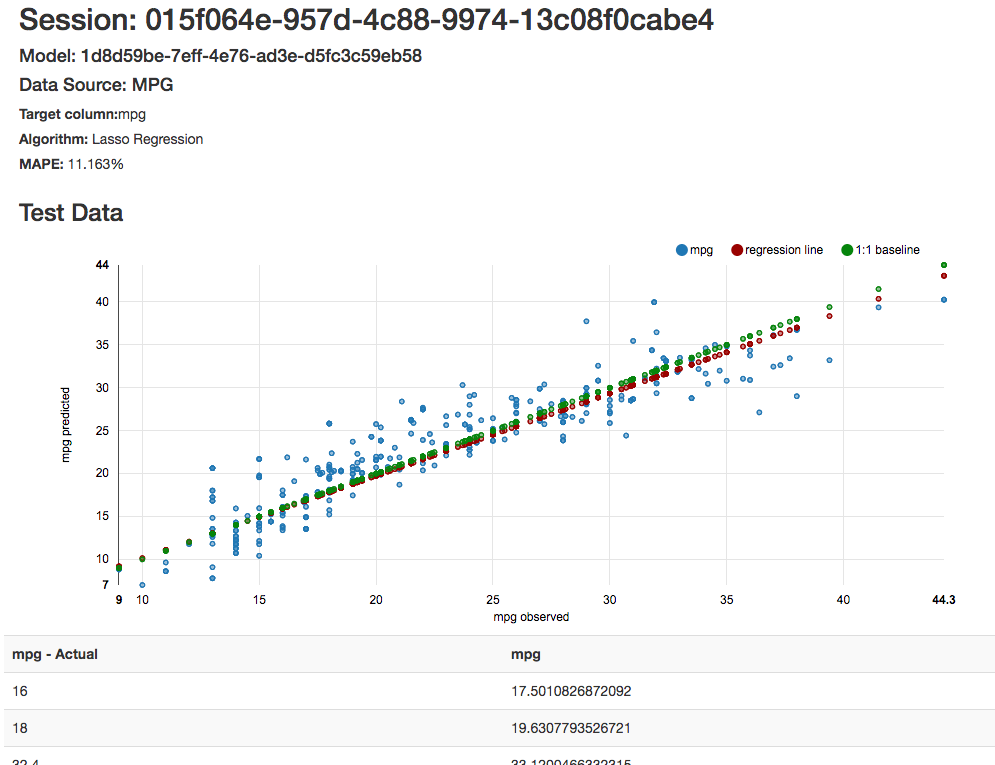
You can see that the plot of predicted vs. actual values lie pretty nicely around the baseline (actual plotted against actual) and we see that the MAPE (an accuracy metric) is about 11% - which is quite good.
Step 3 - Predict
Our session succeeded, and our model looks like it should do a good job; now we’re ready to make predictions. The prediction endpoint is exposed with the modelId as stated above.
To get back predictions we’re going to make an HTTP POST of a JSON data array to
https://ml.nexosis.com/v1/models/{your modelId}/predict
The data array to send is simply everything you originally sent in the DataSet, but without the target column. In this case we can get a prediction for MPG by sending
{
"data": [{
"Cylinders": 4,
"Displacement": 125,
"Horsepower": 100,
"Weight": 2568,
"Acceleration": 17,
"ModelYear": 73,
"Origin": 3,
"Make": "honda"
}]
}
Notice that we are not sending the name field either because it wasn’t a feature. If you send more than one set of values you will get more than one prediction. In this case, let’s just send the one. We get back a data object which now has the MPG field filled in with the prediction
{
"data": [{
"Cylinders": "4",
"Displacement": "125",
"Horsepower": "100",
"Weight": "2568",
"Acceleration": "17",
"ModelYear": "73",
"Origin": "3",
"Make": "honda",
"MPG": "25.9592841499361"
}],
... other model info elided ...
}
And we’re done! Data uploaded, model built, prediction made. Hopefully you’re now ready to go and make something smart of your own with the Nexosis API.
1: Lichman, M. (2013). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
